TL;DR: Grass is a decentralized network for accessing the public web, and thus accessing the data necessary to train AI models. As it expands into the business of cleaning and preparing structured datasets, it becomes an integral part of the basis for AI’s existence - the data layer of AI.
Introduction
Recently, you may have heard people refer to Grass as “The Data Layer of AI.” What does that mean, though?
You’re probably aware that the AI revolution is unfolding as we speak, and you may know that Grass is the easiest way to earn a stake in it while there’s still time. But anything more complicated than that, and - well, that’s when the headaches begin. The subject gets complicated fast, and there’s a lot of noise out there.
And that’s okay. Explaining this stuff is literally our job.
So today we’re going to go into a bit more detail about what the Data Layer of AI is, and explain some of the new services that Grass has started performing recently. Then you’ll have a clearer picture of why 600,000 people seem to think this is a good idea, and why you made the right choice by deciding to get on board. Let’s dive in.
- What is The Data Layer of AI?
What is the Data Layer of AI?
Well, before we even go there, what is AI in the first place? Explain like I’m 5.
Simply put, AI is a program that takes large amounts of data and finds patterns in it. Then, it uses these patterns to make predictions when prompted.
One example: Think of ChatGPT. It takes billions of words and it notices how they each correlate with one another. It sees the word “sky” next to the word “blue” 10 or 15,000 times, and now it can tell you: the sky is blue.
Okay, now pause.
You’ll notice that three things happened in that paragraph.
First, the model acquired the data to be trained on. Second, it combed through it to “learn” all the patterns and correlations it could find. And third, it told you “blue” when you asked what color the sky was.
When you think of an AI protocol, particularly in crypto, you probably think of part two - the training. You think of a decentralized network of processors that the model uses when it combs through data, hunting for patterns. And you’d be right - that’s one kind of AI protocol. The thing is, it’s not the most important part. This next part is, though, so read closely.
While training an AI model is obviously important, the answers you get when you use it are based solely on the correlations it finds in the training data. ChatGPT can tell you the sky is blue only because it encountered that answer enough times in the data it was trained on. If you start with low quality training data, you end up with low quality answers. No training data? No answers.
In other words, you can have the most powerful model on the planet, but if it was trained on two Medium articles that both say the sky is green, guess what your model will tell you when you ask what color the sky is. Bzzzt. Wrong answer.
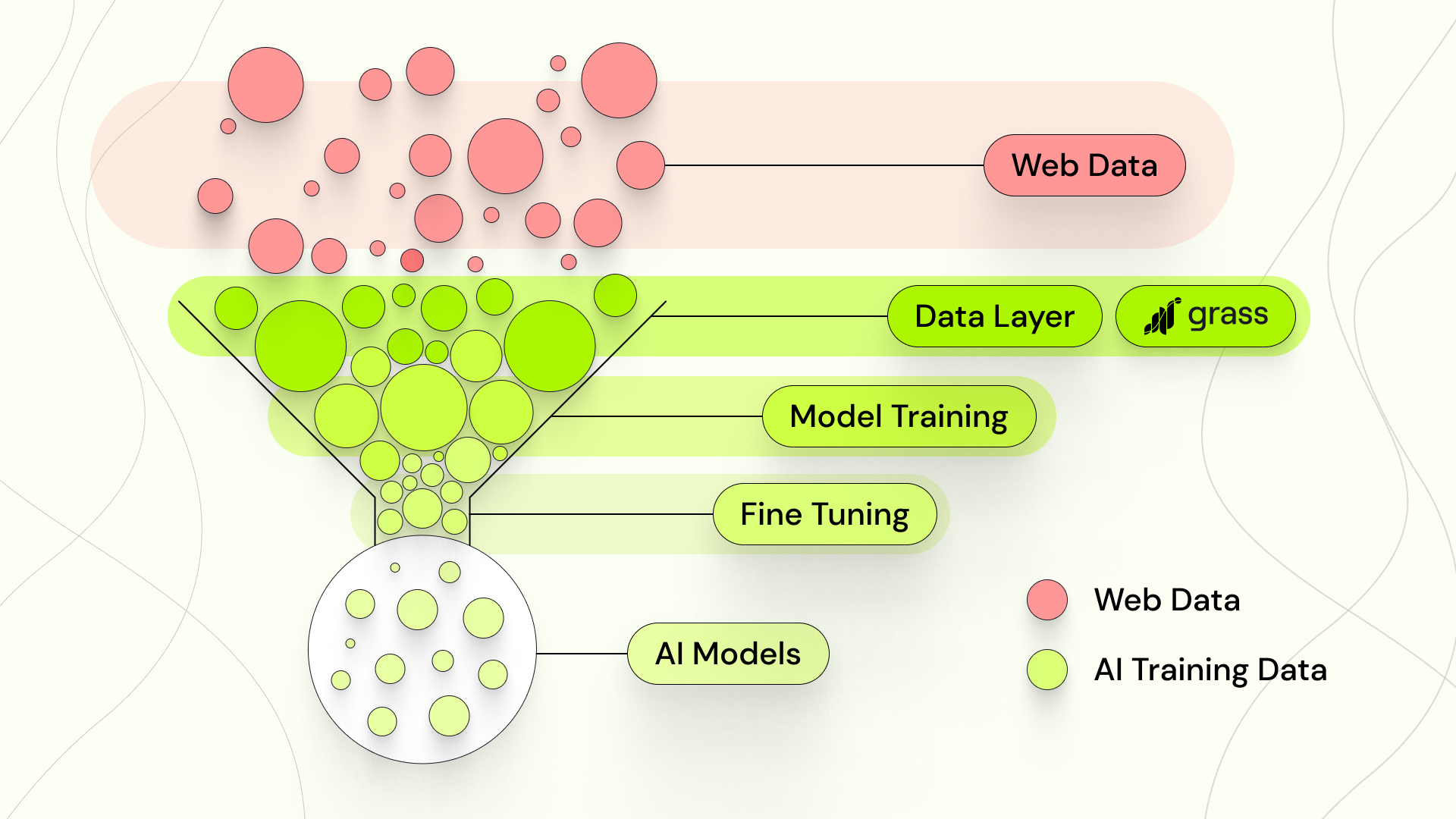
When viewed in this way, the data is actually the most important part of any AI model. Far from being a perfunctory preamble to development, data is actually the core of any functioning model, and data provisioning is the basis for any training. That’s why, according to one report, “Preparing data for AI tools often accounts for up to 80 percent of the total workload involved in implementing AI systems.” Data provisioning is actually most of the battle!
So what is the data layer, then?
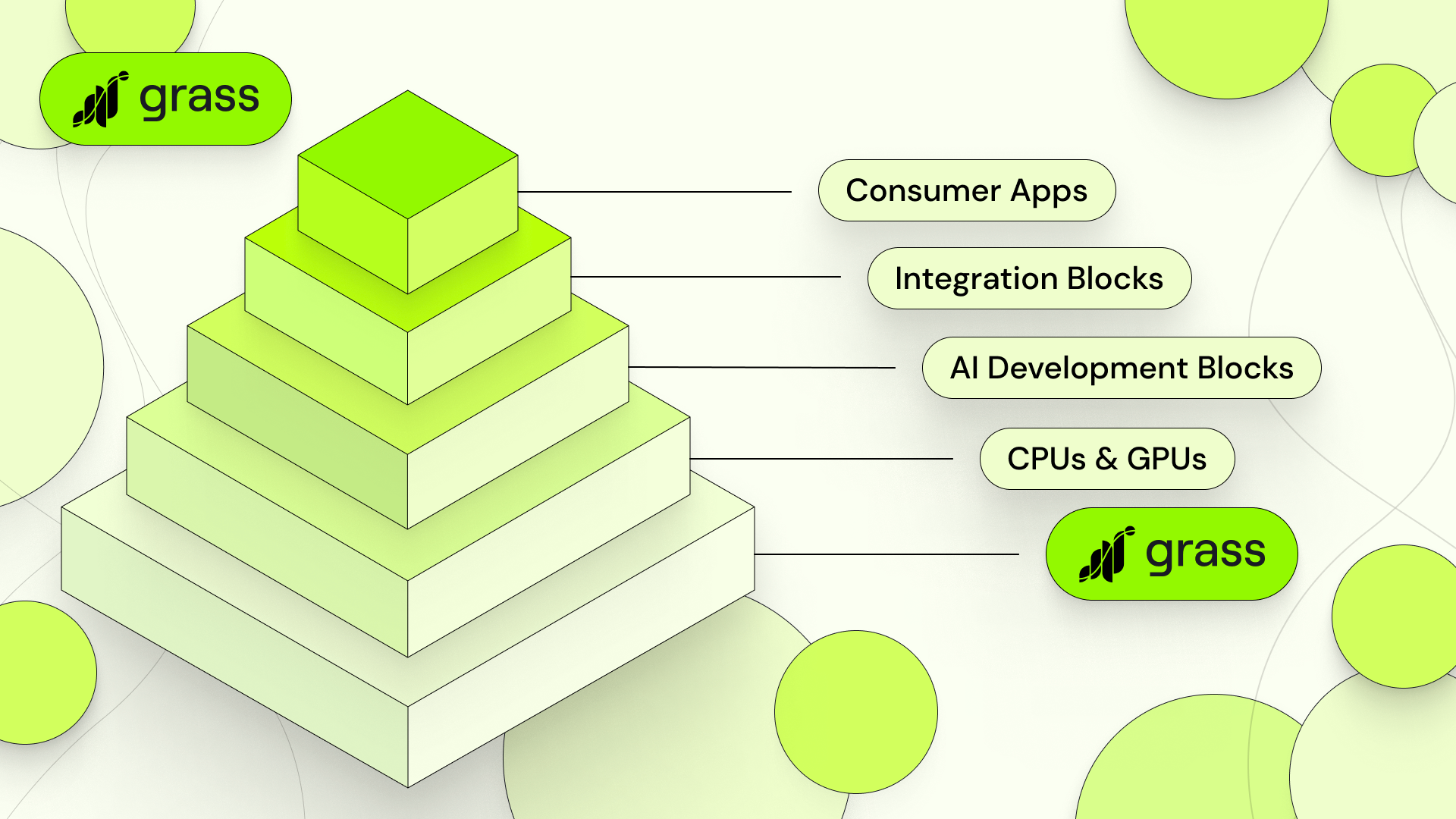
The data layer is that first stage of AI development. It’s the part of the AI stack where data is gathered and prepared for a model, before training even begins. And this, my friends, is Grass. It’s also where you can contribute, and where you can reap some of the benefits of the cambrian explosion of artificial intelligence. So do stay with us. Let’s continue…
- Is Grass used to acquire data for AI training?
We’re glad you asked. Yes, that’s exactly what Grass is used for!
When you run a node on Grass, you’re contributing the portions of your internet connection that aren’t in use. We’re not all streaming video 24 hours a day, so there’s plenty of internet that you pay for, but aren’t using at any given time.
And this is a resource that AI labs will pay for! Using the Grass network, they can go online to view public websites and scrape AI data. This is then used for training purposes, creating tomorrow’s AI models and including ordinary people in the development of AI. It’s really that simple.
- Is Grass used to prepare this data after it’s gathered from the internet?
Yes, when data is scraped from public websites, it arrives unstructured. Picture the language data from a website, only instead of sentences and paragraphs, you see only a string of letters and numbers, thousands of digits long, with no comprehensible order. Structuring data refers to the process of taking these numbers and putting them into a recognizable format - in this example, organizing them so they can actually be read and interpreted. Data needs to be structured in a specific way for an AI model to use it, so this is obviously a critical step in the AI pipeline.
Another component of preparation is cleaning the data. Outliers may skew the results that a model comes up with when it’s learning, so it’s important to throw those out before training begins. Moreover, we’re starting to see more instances of intentional poisoning as the data wars heat up and companies attempt to sabotage each other. They accomplish this by including deliberately false information on their websites, to stymie their opponents when they attempt to scrape each other for corporate intelligence. This is one more reason why data can’t simply be plugged into AI models without careful preparation first.
- Why is a decentralized network necessary to perform these services?
Many of the largest websites in existence have a stake in private, centralized AI companies and a vested interest in preventing smaller competitors from gaining a foothold. Even the ones that don’t have still begun to realize how much their data is worth, and they’ve started instituting policies that make access cost prohibitive for all but the largest AI labs. A huge amount of language data can be drawn from Reddit, for example, but the company began charging exorbitant amounts for their API last year, and now attempts to stop people from scraping it themselves.
In practice, this often works by blocking the IP addresses of known data centers. Many corporations run networks like Grass that are centralized and extractive compared to Grass’s decentralized and equitable design, and these networks often rely on data centers for scraping. Since websites block these IP addresses, the only real way an AI lab can view them is through decentralized networks like Grass.
- How is Grass better than traditional methods of data provisioning?
Grass was built for one reason: because the rise of AI is an opportunity to right some of the wrongs that occurred in Web 2.0. We are unhappy with the way the internet is developing right now, and we believe that building this infrastructure is the best way to promote our values in the development of Web3.
Here are three things we’re proud of:
- Grass is a network that will be owned and operated by its users. When you run a node and earn Grass points, you’re earning a stake in the network itself as you help operate it. Unlike other networks, who incentivize their users with a pittance if they incentivize them at all, Grass is designed to be an equitable and collective project. That means that as AI grows, we all benefit instead of just Bill Gates and Elon Musk.
- Grass is the single easiest way that currently exists for anyone to get exposure to the rise of AI. Running a node is as easy as signing up and installing the Desktop node, and the app does the rest of the work for you. Grass is a passive, rather than active way to participate in AI, meaning anyone can contribute with virtually no effort.
- In addition to its usefulness in training conventional artificial intelligence, Grass is enabling the creation of decentralized and open-source AI by creating alternative pathways for web data to be accessed. If nobody does this, companies like Google and Microsoft will be empowered to gatekeep the public web, as the only entities who have indexed the whole thing. They can then use this power to assert a monopoly on the development of AI, since (as you now know) no training data = no AI model. By providing this service, Grass is working to make public web data accessible to all.
This was a lot of information, but hopefully you have a better sense of the role Grass plays in AI development, what our current mission is, and why we feel it’s so important. By participating with us here, you’re not just getting a stake in the AI revolution for contributing to the network. You’re helping to create a better, fairer, and more just world. Like AI itself, it all begins with the data layer. So thanks for helping us build this infrastructure and create the world we want to live in.
